
Using Python in RevOps: How to Update Your CRM and Avoid Duplicates
See how Python can streamline RevOps tasks, including CRM updates and deduplication, through a real-world case study.

Haris Odobasic
Python can be helpful in Revenue Operations. I like to use it when I have to handle data.
Problem: 300 million pairs to check
We had recently the case, that we had to match a list of 30k accounts to a CRM that already had 10k accounts. You can bet there were tons of duplicates.
The main issue is that the CRM used often the brand name (The Lego Group) vs the legal name (Lego A/S). The new file had only legal names. Bummer.
The issue is we have to compare 300 million possible pairs. This crashes graphical tools like Excel or Google Sheets (at least, it did so for me).
Tip: Before importing any data into the CRM, you want to make sure that your data set is in the best possible shape. Once in the CRM it will become way more time intensive (expensive) to make correction.
Solution: Python & ChatGPT to the rescue
Let me guess: Python sounds intimidating? I thought the same! My coding understanding is for from good. Today, it is easier to learn than ever and ChatGPT is a game changer. In a few months, one can get enough understanding to use it for business use cases (like fuzzy matching).
Approach
You will need the two source files to match. In our case:
file1 - source data from CRM with record ID
file2 - new data from data provider
Tip: Make sure there are no duplicates within each file!
Matching variable
Next, each file should have a matching criteria. In our example they all have a field called "Account Name".
Folder Structure
You want to place both files into the same folder with the script. The results will also be later in the folder.
Fuzzy matching
Fuzzy matching is a method for approximately matching string. In English: it matches similar words. Like in the picture:
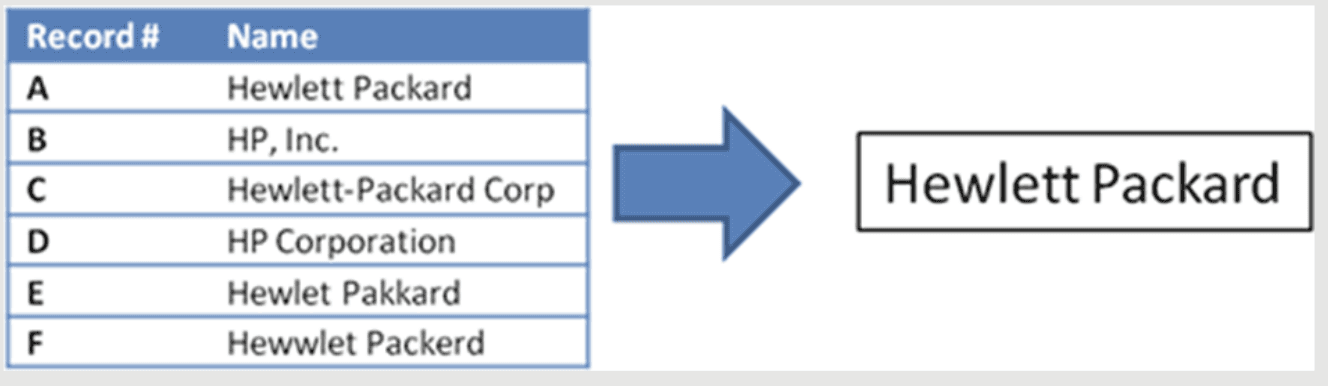
Here a detailed explanation of the concept.
For our purposes, you only need to know that for a fuzzy match, we need to set a matching %. The percentage indicates the max similarity of the words. Examples:
Too high, e.g. 97% then you will miss matches
Too low, e.g. 84% then you have a higher chance of wrong matches.
A good practice is to use 95-90%. See the 90 in the code. That is the number you want to play with.
# Performing the fuzzy matching
dict_list = []
for name in df3['Account Name']:
match = match_name(name, df4['Accont Name'], 90)You can go below 90 but then I would do a few test runs and check the data manually for some odd matches. It all depends on your source data.
Full code
Below you will find the full script. You only need to make a few changes:
Replace the file structure of each file
Replace the matching variable ('Account Name' in this example)
Set the fuzzy matching %
Once you run the code it might take a few minutes to complete.
Hope this was helpful! It saved me countless hours of work and investing into a tall to solve the problem.
import pandas as pd
from fuzzywuzzy import fuzz, process
# Function to match name using fuzzy matching
def match_name(name, list_names, min_score=0):
max_score = -1
max_name = ""
for name2 in list_names:
score = fuzz.ratio(name, name2)
if (score > min_score) & (score > max_score):
max_name = name2
max_score = score
return max_name, max_score
# Reading the data - insert your file structure in there
df3 = pd.read_csv('/Users/harisodobasic/Projects/duplication/file1', encoding='ISO-8859-1')
df4 = pd.read_csv('/Users/harisodobasic/Projects/duplication/file2', encoding='ISO-8859-1')
# Convert the 'Account Name' (insert here your matching variable) columns to strings (had to be done as in some cases strange strings in were in the name)
df3['Account Name'] = df3['Account Name'].apply(lambda x: str(x) if not pd.isnull(x) else '')
df4['Accont Name'] = df4['Accont Name'].apply(lambda x: str(x) if not pd.isnull(x) else '')
# Performing the fuzzy matching
dict_list = []
for name in df3['Account Name']:
match = match_name(name, df4['Accont Name'], 90)
dict_ = {
"Account_Name_df3": name,
"match_name_df4": match[0],
"score": match[1]
}
dict_list.append(dict_)
merge_table = pd.DataFrame(dict_list)
# Merging the fuzzy match results with the original data from df3
final_data = pd.merge(merge_table, df3, how='left', left_on='Account_Name_df3', right_on='Account Name')
# Merging the above result with df4 using an 'outer' join to include unmatched rows from df4
final_data = pd.merge(final_data, df4, how='outer', left_on='match_name_df4', right_on='Accont Name')
# Removing redundant columns
final_data.drop(columns=['Account_Name_df3', 'match_name_df4'], inplace=True)
# Exporting the result to a CSV file
final_data.to_csv('result.csv', index=False)
print("Fuzzy matching completed and results saved to 'result.csv'")Python can be helpful in Revenue Operations. I like to use it when I have to handle data.
Problem: 300 million pairs to check
We had recently the case, that we had to match a list of 30k accounts to a CRM that already had 10k accounts. You can bet there were tons of duplicates.
The main issue is that the CRM used often the brand name (The Lego Group) vs the legal name (Lego A/S). The new file had only legal names. Bummer.
The issue is we have to compare 300 million possible pairs. This crashes graphical tools like Excel or Google Sheets (at least, it did so for me).
Tip: Before importing any data into the CRM, you want to make sure that your data set is in the best possible shape. Once in the CRM it will become way more time intensive (expensive) to make correction.
Solution: Python & ChatGPT to the rescue
Let me guess: Python sounds intimidating? I thought the same! My coding understanding is for from good. Today, it is easier to learn than ever and ChatGPT is a game changer. In a few months, one can get enough understanding to use it for business use cases (like fuzzy matching).
Approach
You will need the two source files to match. In our case:
file1 - source data from CRM with record ID
file2 - new data from data provider
Tip: Make sure there are no duplicates within each file!
Matching variable
Next, each file should have a matching criteria. In our example they all have a field called "Account Name".
Folder Structure
You want to place both files into the same folder with the script. The results will also be later in the folder.
Fuzzy matching
Fuzzy matching is a method for approximately matching string. In English: it matches similar words. Like in the picture:
Here a detailed explanation of the concept.
For our purposes, you only need to know that for a fuzzy match, we need to set a matching %. The percentage indicates the max similarity of the words. Examples:
Too high, e.g. 97% then you will miss matches
Too low, e.g. 84% then you have a higher chance of wrong matches.
A good practice is to use 95-90%. See the 90 in the code. That is the number you want to play with.
# Performing the fuzzy matching
dict_list = []
for name in df3['Account Name']:
match = match_name(name, df4['Accont Name'], 90)You can go below 90 but then I would do a few test runs and check the data manually for some odd matches. It all depends on your source data.
Full code
Below you will find the full script. You only need to make a few changes:
Replace the file structure of each file
Replace the matching variable ('Account Name' in this example)
Set the fuzzy matching %
Once you run the code it might take a few minutes to complete.
Hope this was helpful! It saved me countless hours of work and investing into a tall to solve the problem.
import pandas as pd
from fuzzywuzzy import fuzz, process
# Function to match name using fuzzy matching
def match_name(name, list_names, min_score=0):
max_score = -1
max_name = ""
for name2 in list_names:
score = fuzz.ratio(name, name2)
if (score > min_score) & (score > max_score):
max_name = name2
max_score = score
return max_name, max_score
# Reading the data - insert your file structure in there
df3 = pd.read_csv('/Users/harisodobasic/Projects/duplication/file1', encoding='ISO-8859-1')
df4 = pd.read_csv('/Users/harisodobasic/Projects/duplication/file2', encoding='ISO-8859-1')
# Convert the 'Account Name' (insert here your matching variable) columns to strings (had to be done as in some cases strange strings in were in the name)
df3['Account Name'] = df3['Account Name'].apply(lambda x: str(x) if not pd.isnull(x) else '')
df4['Accont Name'] = df4['Accont Name'].apply(lambda x: str(x) if not pd.isnull(x) else '')
# Performing the fuzzy matching
dict_list = []
for name in df3['Account Name']:
match = match_name(name, df4['Accont Name'], 90)
dict_ = {
"Account_Name_df3": name,
"match_name_df4": match[0],
"score": match[1]
}
dict_list.append(dict_)
merge_table = pd.DataFrame(dict_list)
# Merging the fuzzy match results with the original data from df3
final_data = pd.merge(merge_table, df3, how='left', left_on='Account_Name_df3', right_on='Account Name')
# Merging the above result with df4 using an 'outer' join to include unmatched rows from df4
final_data = pd.merge(final_data, df4, how='outer', left_on='match_name_df4', right_on='Accont Name')
# Removing redundant columns
final_data.drop(columns=['Account_Name_df3', 'match_name_df4'], inplace=True)
# Exporting the result to a CSV file
final_data.to_csv('result.csv', index=False)
print("Fuzzy matching completed and results saved to 'result.csv'")Python can be helpful in Revenue Operations. I like to use it when I have to handle data.
Problem: 300 million pairs to check
We had recently the case, that we had to match a list of 30k accounts to a CRM that already had 10k accounts. You can bet there were tons of duplicates.
The main issue is that the CRM used often the brand name (The Lego Group) vs the legal name (Lego A/S). The new file had only legal names. Bummer.
The issue is we have to compare 300 million possible pairs. This crashes graphical tools like Excel or Google Sheets (at least, it did so for me).
Tip: Before importing any data into the CRM, you want to make sure that your data set is in the best possible shape. Once in the CRM it will become way more time intensive (expensive) to make correction.
Solution: Python & ChatGPT to the rescue
Let me guess: Python sounds intimidating? I thought the same! My coding understanding is for from good. Today, it is easier to learn than ever and ChatGPT is a game changer. In a few months, one can get enough understanding to use it for business use cases (like fuzzy matching).
Approach
You will need the two source files to match. In our case:
file1 - source data from CRM with record ID
file2 - new data from data provider
Tip: Make sure there are no duplicates within each file!
Matching variable
Next, each file should have a matching criteria. In our example they all have a field called "Account Name".
Folder Structure
You want to place both files into the same folder with the script. The results will also be later in the folder.
Fuzzy matching
Fuzzy matching is a method for approximately matching string. In English: it matches similar words. Like in the picture:
Here a detailed explanation of the concept.
For our purposes, you only need to know that for a fuzzy match, we need to set a matching %. The percentage indicates the max similarity of the words. Examples:
Too high, e.g. 97% then you will miss matches
Too low, e.g. 84% then you have a higher chance of wrong matches.
A good practice is to use 95-90%. See the 90 in the code. That is the number you want to play with.
# Performing the fuzzy matching
dict_list = []
for name in df3['Account Name']:
match = match_name(name, df4['Accont Name'], 90)You can go below 90 but then I would do a few test runs and check the data manually for some odd matches. It all depends on your source data.
Full code
Below you will find the full script. You only need to make a few changes:
Replace the file structure of each file
Replace the matching variable ('Account Name' in this example)
Set the fuzzy matching %
Once you run the code it might take a few minutes to complete.
Hope this was helpful! It saved me countless hours of work and investing into a tall to solve the problem.
import pandas as pd
from fuzzywuzzy import fuzz, process
# Function to match name using fuzzy matching
def match_name(name, list_names, min_score=0):
max_score = -1
max_name = ""
for name2 in list_names:
score = fuzz.ratio(name, name2)
if (score > min_score) & (score > max_score):
max_name = name2
max_score = score
return max_name, max_score
# Reading the data - insert your file structure in there
df3 = pd.read_csv('/Users/harisodobasic/Projects/duplication/file1', encoding='ISO-8859-1')
df4 = pd.read_csv('/Users/harisodobasic/Projects/duplication/file2', encoding='ISO-8859-1')
# Convert the 'Account Name' (insert here your matching variable) columns to strings (had to be done as in some cases strange strings in were in the name)
df3['Account Name'] = df3['Account Name'].apply(lambda x: str(x) if not pd.isnull(x) else '')
df4['Accont Name'] = df4['Accont Name'].apply(lambda x: str(x) if not pd.isnull(x) else '')
# Performing the fuzzy matching
dict_list = []
for name in df3['Account Name']:
match = match_name(name, df4['Accont Name'], 90)
dict_ = {
"Account_Name_df3": name,
"match_name_df4": match[0],
"score": match[1]
}
dict_list.append(dict_)
merge_table = pd.DataFrame(dict_list)
# Merging the fuzzy match results with the original data from df3
final_data = pd.merge(merge_table, df3, how='left', left_on='Account_Name_df3', right_on='Account Name')
# Merging the above result with df4 using an 'outer' join to include unmatched rows from df4
final_data = pd.merge(final_data, df4, how='outer', left_on='match_name_df4', right_on='Accont Name')
# Removing redundant columns
final_data.drop(columns=['Account_Name_df3', 'match_name_df4'], inplace=True)
# Exporting the result to a CSV file
final_data.to_csv('result.csv', index=False)
print("Fuzzy matching completed and results saved to 'result.csv'")Stay updated with our Revenue Blog
Stay updated with our Revenue Blog
View all Posts

The Best Revenue Operations Books Worth Your Time
Jul 28, 2026
Three revenue operations books worth your time. Revenue Architecture, The RevOps Pendulum, and Influence by Cialdini.

How To Find The Right Revenue Operations Consulting Partner
Jul 20, 2026
The right revenue operations consultant bridges the gap between where you are and where you need to be. The wrong one is an expensive distraction. Here is how to choose.

Why AI Makes The Revenue Operations Strategy More Critical
Jul 15, 2026
AI-native startups run $2-4M revenue per employee. Traditional SaaS runs $300K. The gap is revenue operations strategy. Here is why AI makes it more critical.
Load More


